学一个新东西,我会怎么开始
学一个新东西,我会怎么开始
标签:#博客 #思考笔记 #信息收集 #学习方法
这篇文章讲什么
接到一个陌生任务,或者想学一个完全不懂的东西,第一步应该做什么?
很多人的反应是:
打开浏览器,搜关键词
然后看一下午,啥也没学到。
这篇讲讲我有关"怎样开始"的思考。
先看一个很常见的问题
导师说:
你看看强化学习能不能用在车辆控制里。
很多人接到这种任务,第一反应是去 Google Scholar 搜:
reinforcement learning vehicle control
搜出来几千篇论文,从第一篇开始读,读 3 小时,出来:
- 不知道领域分几支
- 不知道谁是关键人物
- 不知道现在的热点是什么
- 也没记住自己读过什么
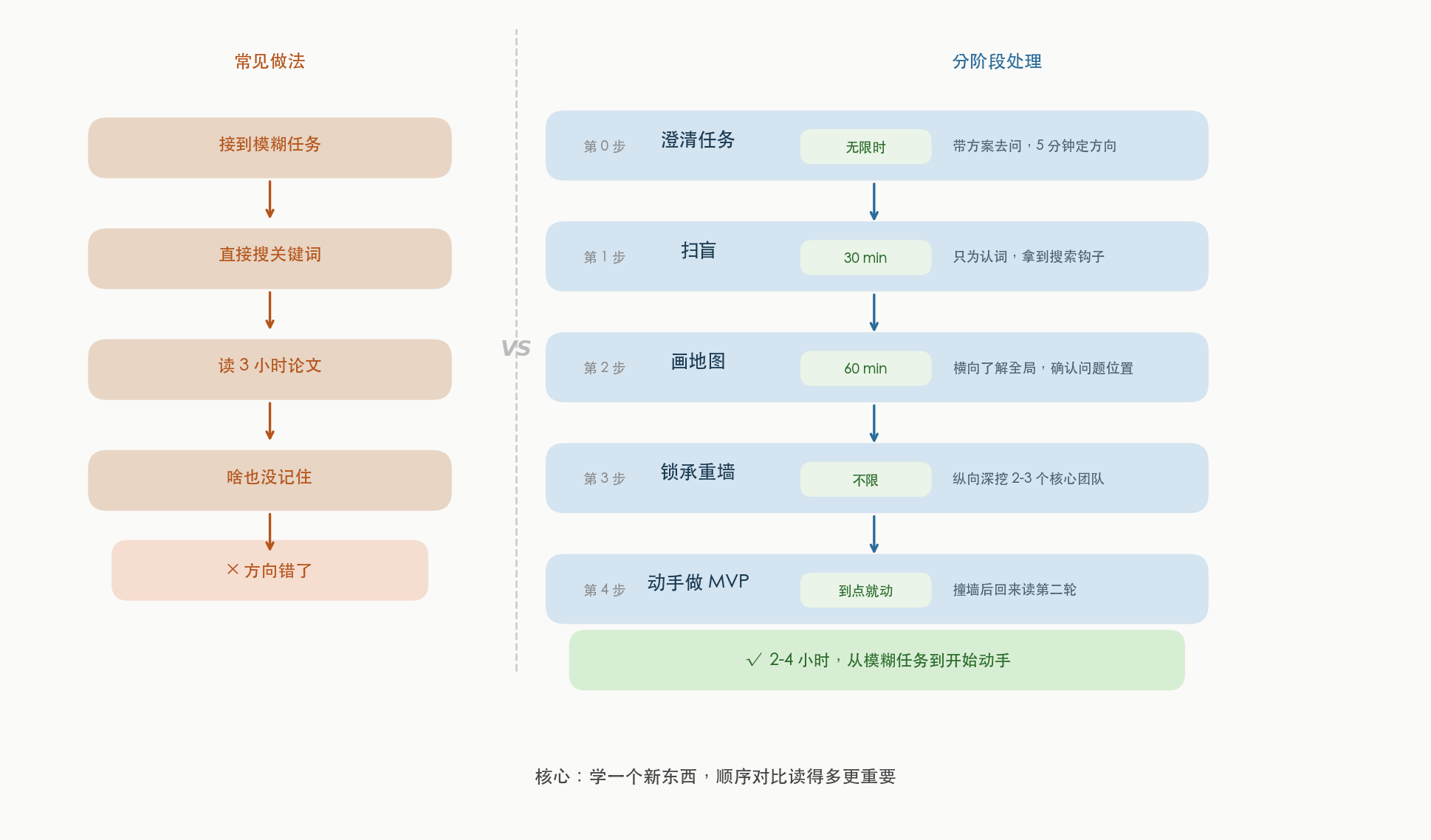
问题不在"读得不够多",问题在方向错了。
调研的根本矛盾
入门一个新领域有一个绕不开的矛盾:
你需要先懂一点,才能问出好问题
但你正是因为不懂才需要去查
这不是 bug,是结构性问题。
正确的做法是承认这个矛盾,然后分阶段处理。
每个阶段目标不同,信源也不同。
第 0 步:澄清任务
如果任务是别人交给你的,不要直接开始调研。
先去问。
但不是问:
您是想让我做 A 还是 B?
这是把决策推回给对方。
应该是:
我理解任务可以两种切法:
A. ...
B. ...
我倾向 A,因为 ...
您看?
带方案 = 你思考过了 = 5 分钟解决。
不带方案 = 你期待对方告诉你怎么做 = 对方烦,你低效。
布置任务的人脑子里通常有你不知道的约束:经费、合作方、时间窗口。
你直觉再准,也猜不到这些。
第 1 步:扫盲
任务澄清完,但你可能对这个领域还是一无所知。
这时候不要立刻去搜论文。
先做一轮扫盲。
扫盲的目标只有一个:
认词
不是学懂,只是认词。
因为下一步要搜更精确的东西,没有关键词就搜不到精确的东西。
具体动作:
| 信源 | 时间 | 目的 |
|---|---|---|
| 维基百科词条 | 5 分钟 | 看分类、看术语 |
| 15 分钟科普视频(1.5 倍速) | 10 分钟 | 看直觉、看应用 |
| 一篇综述的摘要 + 引言 + 结论 | 15 分钟 | 看分类,跳过正文 |
总时间:30 分钟,严格限时。
产出:你嘴里能说出 5-10 个这个领域的关键术语。
这一步严禁的事:
深挖某一个术语
做笔记做到完美
看到有趣的论文就精读
扫盲只是为了拿到下一步的搜索钩子。
不限时就会无限往深处沉,最后变成"假装自己在调研"。
第 2 步:画地图
扫盲完,你能说出几个关键词了。
但你还不知道这些词在整个领域里是什么位置。
有个比喻:
陌生领域像一座山
新手一上来就找一棵树研究(钻井)
老手先爬到山顶看地形(地图)
画地图的时间盒:60 分钟。
画完后,你要能用一张纸回答:
- 这个领域分几个主要方向?
- 每个方向的代表方法、代表人物、代表团队?
- 当前热点在哪?瓶颈在哪?
- 我的具体问题落在地图的哪个位置?
最后一问最关键。
如果你的问题在地图上找不到对应位置,说明问题本身还得改。
信源:
| 信源类型 | 找法 |
|---|---|
| 近 2-3 年综述(1-2 篇) | 顶刊优先,Google Scholar 按引用排序 |
| GitHub awesome-X 列表 | 搜 awesome 领域名 |
| 顶会 tutorial 第一节 | B 站搜领域名 |
| position / perspective 论文 | 可选,看争议和瓶颈 |
读综述的方式:
只读三部分:
- 摘要
- 引言里的分类图
- 结论里的 future work
正文跳过,留给下一步。
这一步严禁的事:
精读任何论文
跑代码、复现
写自己的方案
看到好东西标"待读",别动。
第 3 步:锁承重墙
地图画完,但不能开始精读所有论文。
任何细分方向真正撑场的,通常就 2-3 个人 / repo / 论文。
这些就是承重墙。
找到它们,顺着挖,信息密度是散读的 10 倍。
怎么找承重墙:
综述里被反复引用、被当 baseline 的论文
多个综述都提到的同一团队或个人
GitHub 上 star 多、fork 多、issue 活跃的 repo
挖法:
核心人物的 Google Scholar 主页 → 近 3 年所有论文标题扫一遍
核心 repo 的 commit history、issues、README → 看做什么、用什么 baseline
核心论文的被引用网络 → 接下来谁在做什么
信源这时候切到一手:论文原文、源码、GitHub issues、作者本人博客。
散读和顺挖的区别:
散读:看 20 篇论文,记住 0 篇
顺挖:跟 3 个核心团队的近 10 篇,记住 7 篇,还知道他们之间的关系
第 4 步:动手做 MVP
调研做到这里,你可能想继续往深读。
不要。
给整个调研一个总时间盒(2-4 小时),到点就动手。
"我再读一篇就开始" = 逃避
第一轮调研只是为了让你能动手,不是为了让你懂透。
撞墙之后回来读第二轮,带着具体问题读,效率是第一轮的 5 倍。
信息收集和实操是交替的,不是先收集完再动手。
一个完整例子
还是刚才那个任务:
导师说,你看看强化学习能不能用在车辆控制里。
第 0 步:澄清任务
带方案去问导师:
我理解这个任务可以两种切法:
A. 接入我现在的 platoon,把 MPC 换成或混合 RL,延续现有工作
B. 开一个新场景,比如变道决策或端到端
我倾向 A,因为可以复用现有仿真和实车环境
您看?
导师回:走 A,实车方向,过程中找创新点投会议。
第 1 步:扫盲(30 分钟)
- 维基"强化学习"词条
- B 站"强化学习是什么"科普,1.5 倍速
- 一篇 RL 综述的摘要 + 引言
产出术语:
策略、奖励函数、value-based、policy-based、PPO、SAC、
sim-to-real、safe RL、model-based RL、learning-based MPC
第 2 步:画地图(60 分钟)
读一篇"RL for Autonomous Driving"综述,只看分类和 future work。
画出地图:
RL 在车辆控制里大致分几支:
- RL 直接控制:端到端,sim-to-real 难
- 高层决策 RL + 底层 MPC 执行
- RL 调 MPC 参数
- Learning-based MPC:用 RL 学动力学模型
- Safe RL:MPC 当 safety filter
发现:
我的问题落在「RL 与 MPC 在 platoon 间距控制中的结合方式」
这比一开始的"RL 能不能用"具体多了。
第 3 步:锁承重墙
找到 platoon + RL 的核心工作集中在某 2-3 个团队。
顺着他们的 Google Scholar 主页扫近 3 年论文,找到 5 篇核心论文 + 2 个 GitHub repo。
第 4 步:动手
不再继续读。
打开 CARLA,把现有 platoon 仿真改一个版本,试着接一个最简单的 RL 训练 loop,看跑不跑得通。
撞墙后回来读第二轮。
总耗时:从接到任务到开始动手,大约 3 小时。
不同阶段用什么信源
| 阶段 | 推荐信源 | 不推荐 |
|---|---|---|
| 扫盲期 | 维基、科普视频、综述摘要 | 论文原文 |
| 画地图期 | 综述、awesome 列表、tutorial | 单篇论文精读 |
| 深入期 | 论文原文、源码、GitHub issues | 中文公众号、二手解读 |
| 争议期 | 作者本人 Twitter、个人博客、批评者反驳 | 综述(滞后) |
总原则:
论文原文 > 源码 > GitHub Issues > 作者本人博客 > 二手解读 > 中文公众号
容易踩的坑
1. 跳过澄清,直接开搜 → 几周做错方向
2. 扫盲期想学懂 → 目标错位,30 分钟变 3 小时
3. 跳过画地图直接精读论文 → 看到一棵树以为是森林
4. 没承重墙,散读 20 篇 → 不如顺着 2-3 个核心团队挖
5. 一直读不动手 → 信息越读越多,行动越拖越久
6. 写问题时预设结论 → 把调研做窄
7. 靠直觉代替和布置人确认 → 布置人有你不知道的约束
8. 不限时间盒 → 每一步都会无限拖
总结
学一个新东西,核心不是读得多,而是顺序对。
完整流程:
模糊任务
↓
澄清任务
↓
扫盲
↓
画地图(横向)
↓
锁承重墙(纵向)
↓
动手做 MVP